

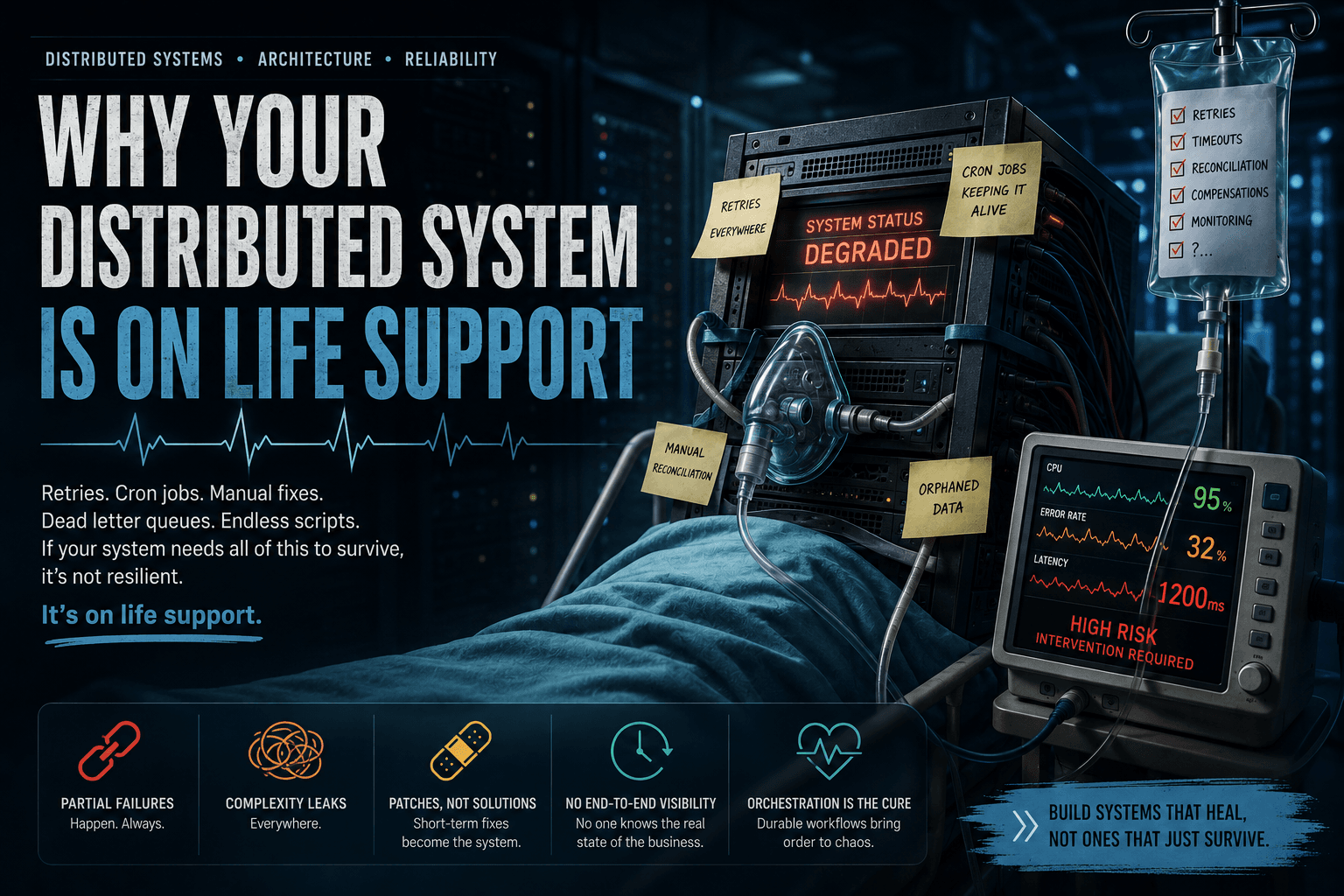
Why Your Distributed System Is on Life Support
Some systems crash.
And then there are far more dangerous systems: the ones that keep running even though they no longer really know what they're doing.
They still respond to requests. The dashboards are sometimes green. The pods are running. The services still expose their endpoints. Messages keep flowing.
But behind this appearance of stability, the system survives on crutches: retries everywhere, repair cron jobs, reconciliation scripts, dead letter queues drained by hand, intermediate statuses that no one understands anymore, support procedures to fix production inconsistencies.
That's what I call a distributed system on life support.
It's not fully dead.
But it's no longer breathing on its own.
The problem isn't the failure — it's the ambiguity
In a distributed system, the greatest danger isn't always the visible crash.
A clean crash is brutal, but it's clear. The service stops responding. The pod restarts. The alert fires. The team intervenes.
The real danger is ambiguity.
Take a simple example: a user clicks "Pay."
The backend calls a payment provider. The provider responds too slowly. Your API times out. You show the user: "payment failed."
But a few seconds later, the provider actually captures the payment.
Now your system has to answer a critical question:
Did the customer pay or not?
And if your system can't answer that clearly, you don't just have a technical problem. You have a business problem.
A payment may have been captured without an order being created. Stock may have been reserved without an invoice generated. A KYC document may have been validated by an external provider without your system recording the decision. An offline sync may have partially succeeded without you knowing exactly which data was applied.
This is where distributed gets hard.
Not because a service can fail. But because one step can succeed while the next one fails.
The lost comfort of the transactional monolith
To understand why our systems end up on life support, we need to go back to the simple world: the transactional monolith.
In a classic architecture, you often had:
Client → Application → Database
One application. One main database. One local transaction.
For an order, you could do:
BEGIN;
INSERT INTO orders;
UPDATE stock;
INSERT INTO payment_attempts;
INSERT INTO invoices;
COMMIT;
If everything succeeded, you committed. If a step failed, you rolled back.
The important point here isn't SQL. The important point is that the system had a clear boundary between success and failure.
Either the order existed completely. Or it didn't exist at all.
Business state was localized. The decision was centralized. The rollback was understandable.
Then the system grows.
You split out payments. You split out stock. You split out billing. You split out notifications. You add external providers. You add queues. You add workers. You add Kubernetes. You add multiple databases.
And at that point, the local transaction explodes.
Your order is no longer a simple operation. It becomes a distributed process.
Order Service → Inventory Service → Payment Provider → Billing Service → Notification Service
And in this world, there is no magic global rollback.
If the payment was captured by an external provider, but your Order Service crashes right after — you can't just ROLLBACK.
The outside world has already changed.
The symptoms of a system on life support
A system on life support isn't recognized by its crashes.
It's recognized by its survival mechanisms.
You've probably already seen this kind of thing:
cron_repair_orders
retry_failed_payments
manual_reconciliation_script
pending_status_cleanup
dead_letter_reprocessor
fix_orphan_transactions
At first, these mechanisms seem reasonable.
A cron job to replay stuck orders. A DLQ ( dead letter queue ) to store failed messages. A script to reconcile payments. A status table to track steps.
But over time, these fixes become the actual architecture of the system.
The business workflow is no longer in the main code. It's scattered across services, queues, databases, statuses, scripts, crons, human procedures, dashboards, and support interventions.
And when an incident happens, the question becomes very simple:
Where is the truth of the process?
In the payment service? In the orders table? In the queue? In the DLQ? In the logs? In a reconciliation script? In the head of a senior developer who knows the project history?
If the answer isn't clear, your system may still be breathing — but it's already on life support.
Retries are not a reliability strategy
The first reflex when facing an error is often: "let's retry."
That's normal.
But in a distributed system, a retry can be a solution or a bomb.
Imagine an operation like:
ChargeCreditCard(customerId, amount)
If the call times out, what do you actually know?
You don't know if the payment failed. You don't know if it succeeded. You don't know if the response was lost. You don't know if the provider is still processing the operation.
If you naively replay the call, you risk charging twice.
So the real question isn't: should we retry?
The real question is: can this operation be replayed safely?
That's the role of idempotency.
An idempotent operation can be repeated multiple times without changing the final result beyond the first execution.
For example, instead of saying:
Charge this customer 10,000 FCFA
you say:
Execute transaction PAYMENT-123 once
If transaction PAYMENT-123 has already been processed, the system returns the same result instead of creating a new charge.
Without idempotency, your retries aren't resilience.
They're incident multipliers.
CAP is not a slogan — it's a warning
At this point, we can talk about the CAP theorem https://en.wikipedia.org/wiki/CAP\_theorem.
Not as a slogan like "choose two out of three." That version is too simplistic.
CAP states a fundamental constraint: in a distributed system, when a network partition occurs, you cannot simultaneously guarantee perfect strong consistency and perfect availability.
In other words, if two parts of the system can no longer communicate, you have to choose.
Either you keep accepting certain operations, with the risk of temporary divergence. Or you block certain operations to preserve stricter consistency.
Simple example: two regions, Brazzaville and Paris, manipulate the same balance.
The customer has 100,000 FCFA.
The network between the two regions goes down.
During the outage, an operation tries to withdraw 80,000 FCFA in Brazzaville. Another tries to withdraw 50,000 FCFA in Paris.
If both regions accept locally, the system stays available, but the global balance becomes inconsistent.
If each region requires global validation before authorizing the withdrawal, some operations will be blocked during the partition.
CAP doesn't tell you how to build your entire architecture.
It simply reminds you that perfect guarantees don't come for free.
And most importantly, it forces you to ask the right question:
What should my system do during the failure, and how should it recover after?
The Saga: stop believing in magic rollbacks
When you leave the transactional monolith, you lose the global rollback.
This is where the Saga pattern comes in.
A Saga is a long business transaction split into multiple local transactions.
Each step commits its change locally. If a later step fails, you execute compensation actions.
E-commerce example:
1. Reserve stock
2. Capture payment
3. Create order
4. Generate invoice
5. Send confirmation
Now imagine:
1. Reserve stock → OK
2. Capture payment → OK
3. Create order → FAIL
In a monolith, you would have rolled back.
But here, the payment already exists at an external provider.
The Saga says: compensate.
Compensations:
- Refund the payment
- Release the stock
- Mark the order as failed
But be careful: a compensation is not a magic rollback.
A rollback gives the impression that the operation never existed.
A compensation is a new business operation that tries to bring the system back to an acceptable state.
Refunding a payment is not the same as never having charged. Canceling a reservation is not the same as never having reserved. Sending a cancellation email doesn't erase the original email. Issuing a credit note is not deleting an invoice.
This is why a Saga is not just a technical pattern.
It's a business discussion.
The trap of hidden Sagas
Many systems already have Sagas.
But they're implicit.
They're hidden in:
statuses like PENDING, FAILED, RETRYING, UNKNOWN
repair scripts
manual processes
support procedures
Kafka consumers
cron jobs
tracking tables
DLQs The problem isn't that these tools exist.
The problem is that the overall business process isn't explicit.
No one can look at a process instance and immediately say:
Step 1: succeeded
Step 2: succeeded
Step 3: failed
Compensation 2: in progress
Compensation 1: pending
Final state: not reached
When the global process state is scattered, operations become difficult.
And when operations become difficult, the system starts breathing artificially.
Event-driven doesn't mean controlled
Event-driven architectures are powerful.
Kafka, RabbitMQ, Pulsar, SQS and other tools allow you to decouple services, absorb load, distribute events, and build asynchronous pipelines.
But there's a common confusion:
A durable message is not a durable business process.
A queue can guarantee that a message doesn't easily disappear. But it doesn't guarantee that the business workflow is complete.
A DLQ can store failed messages. But it doesn't decide how to repair the business state.
A topic can contain the event history. But it doesn't necessarily give you a clear view of the current state of a business instance.
Over time, a poorly controlled event-driven architecture can become event spaghetti:
OrderCreated → InventoryReserved → PaymentCaptured → InvoiceRequested
→ InvoiceFailed → RefundRequested → RefundFailed → ManualReviewCreated
Each service understands its small piece.
But no one controls the entire process anymore.
The real question: where does the workflow state live?
This is the central question.
When a business process crosses multiple services, multiple databases, and multiple external systems — you need to know where its global state lives.
Is it in an orders table? In a Kafka topic? In a consumer? In Redis? In a cron? In a DLQ? In the logs? In a human procedure?
If the workflow state is everywhere, it's nowhere.
And that's where a distributed system becomes fragile.
Not because it doesn't have enough tools.
But because it doesn't have a clear execution model.
Why workflow engines exist
A workflow engine is a system that coordinates and tracks the execution of multi-step business processes, especially when those processes are long-running, distributed, or failure-prone.
It exists because real-world operations rarely finish in one simple transaction. A workflow may call external APIs, wait for human approval, retry failed tasks, handle timeouts, and resume after crashes.
Tools like Temporal, Cadence, AWS Step Functions, Camunda, Conductor, Restate, and Azure Durable Functions help developers make these processes reliable by persisting execution state, managing retries, handling failures, and allowing workflows to continue from where they stopped instead of starting over or getting lost.
How do you durably execute a long, distributed, fallible, and observable business process?
A good workflow engine should allow you to:
persist execution state
resume after a crash
manage retries
manage timeouts
wait for external events
orchestrate multiple services
execute compensations
observe history
version long-running processes This is where tools like Temporal become interesting.
Temporal should not be presented as a magic wand.
Temporal doesn't eliminate failures. Temporal doesn't make your external providers reliable. Temporal doesn't replace idempotency. Temporal doesn't decide your business rules.
But Temporal brings something very valuable:
A durable, explicit, and observable model for driving the execution of a distributed workflow.
Temporal: making execution durable
Temporal is built on a powerful idea: durable execution.
You write a workflow as code.
But this workflow doesn't depend on the fragile memory of a process.
Its execution state is persisted in Temporal.
If a worker crashes, the workflow isn't lost. If an Activity fails, it can be retried according to an explicit policy. If the workflow waits for a human validation for three days, it doesn't need to keep a thread blocked for three days. If the system restarts, Temporal can reconstruct the logical state of the workflow from its history.
The basic model is simple:
Workflow = durable orchestration logic
Activity = fallible external operation
Worker = process that executes workflows and activities
Event History = durable execution history The workflow decides.
The Activity acts.
The workflow says:
1. Launch OCR
2. Launch Face Match
3. Wait for AML result
4. If uncertain, wait for human validation
5. Produce final decision
The Activities make the actual calls:
Call OCR provider
Call payment API
Write to database
Send email
Call AI model
This separation is fundamental.
External calls are fallible, non-deterministic, subject to timeouts and retries. They must live in Activities.
The workflow itself must remain deterministic so it can be replayed.
Temporal doesn't replace rigor
Temporal is not an excuse to write bad design.
On the contrary, Temporal makes your choices explicit.
You still need to think about:
Activity idempotency
Timeouts
Retryable vs non-retryable errors
History size
Workflow versioning
Business compensations
Observability
Security
Data governance Temporal doesn't automatically turn bad architecture into good architecture.
But it gives you a clear place to express the process.
And often, that's exactly what's missing in systems on life support.
Use case 1: KYC as a Service
Let's take a KYC system.
The workflow might look like this:
1. User submits documents
2. ID card OCR
3. Face verification
4. Liveness detection
5. AML / sanctions screening
6. If uncertain score: human validation
7. Final decision
There are many possible failures:
OCR provider unavailable
Face matching model too slow
AML screening timeout
User leaves the application
Human validation after two days
AI worker crashes during processing Without durable orchestration, the KYC state is often scattered.
With Temporal, you can model a KYCWorkflow.
The workflow can wait for human validation, resume after a crash, preserve the step history, retry external providers, and produce an observable final decision.
The key point:
A KYC is not an HTTP request. It's a long-running process.
And a long-running process needs durable state.
Use case 2: Payment
Payment is probably the most telling example.
Workflow:
1. Reserve stock
2. Capture payment
3. Create order
4. Generate invoice
5. Notify customer
Possible failures:
Payment provider timeout
Payment captured but response lost
Order not created after payment
Invoice failed
Email not sent
Worker crash after external side effect Here, Temporal alone is not enough.
The payment Activity must be idempotent.
The provider must receive a unique key, for example order_id.
This way, if the call is replayed, the provider understands it's the same logical operation.
Then the workflow can handle the rest:
If CreateOrder fails:
RefundPayment
ReleaseInventory
MarkOrderAsFailed
Payment teaches an essential lesson:
Reliability doesn't come from retrying alone. It comes from controlled, idempotent retries within a durable workflow.
Use case 3: Offline synchronization
Consider an application that works offline.
Field agents capture data on the ground:
Identity
Documents
Photos
Biometrics
Local mutations
Partial validations During offline mode, the local system remains available but diverges from the server.
On reconnection, synchronization is needed.
Workflow:
1. Detect reconnection
2. Send local batches
3. Deduplicate mutations
4. Validate data
5. Sync large files
6. Resolve conflicts
7. Confirm convergence
Possible failures:
Unstable network
Partially sent batch
Corrupted file
Duplicate mutation
Server crash during merge
Conflict between local and server versions Here, Temporal can orchestrate synchronization:
Split batches
Track chunks
Retry uploads
Launch child workflows
Wait for human resolution in case of conflict
Resume after crash But Temporal doesn't choose the business conflict strategy.
It doesn't decide whether you should do last-write-wins, semantic merge, or human arbitration.
It durably orchestrates the strategy you've defined.
Use case 4: AI pipeline
A modern AI pipeline is rarely a single operation.
Example:
1. Upload PDF
2. OCR
3. Chunking
4. Embeddings
5. Vector indexing
6. LLM call
7. Report generation
8. Human validation
9. Publication
Possible failures:
OCR timeout
LLM provider rate limited
Embeddings worker crash
Document too large
Provider cost too high
Delayed human validation
Non-deterministic result Temporal is well suited for this kind of pipeline, provided you follow one rule:
AI calls must not be directly in the workflow. They must be in Activities.
The workflow describes the plan.
The Activities execute non-deterministic operations.
This is what allows you to retry, observe, resume, and control the pipeline without losing global state.
Conclusion: breathing without assistance
A robust distributed system isn't one that never fails.
It's one that knows what to do when part of it fails.
It knows what has already been done. It knows what needs to be resumed. It knows what needs to be compensated. It knows what must not be replayed. It knows how to explain its own state.
A system on life support survives through implicit mechanisms: crons, scripts, DLQs, manual procedures, opaque statuses, overnight corrections.
A resilient system makes these mechanisms explicit.
It turns chaos into workflow. It turns retries into policies. It turns manual repairs into compensations. It turns ambiguity into observable history.
The real question isn't:
Can my system fail?
The real question is:
When it fails in the middle of a business process, does it still know how to breathe on its own?